How a 5-person team shipped 800 deployments in April — and why velocity without guardrails is the most expensive mistake in fintech.
“The world needs so much more code than currently gets written.”
— Sam Altman, Stripe Sessions, April 30, 2026
In April 2026, our engineering team at Rexi shipped 800 deployments to production.
We are five people. Including me.
Before you assume this post is about speed, let me reframe the number.
800 deployments isn’t 800 features. It’s 800 iterations of the product: new features, bug fixes, refactors, rollbacks, micro-improvements, schema migrations, infrastructure tweaks. It’s 800 times we said “this is good enough to put in front of customers” — and meant it.
The reason that number matters isn’t velocity.
It’s what 800 iterations require to be safe.
When AI started accelerating our output, we hit a wall.
Not a technical wall. A process wall.
In December 2025, we had a PR storm. Pull requests started piling up at a rate we’d never seen. Our policy was sacred — and rightly so for a fintech: every PR required two human approvals before merge.
That rule wasn’t wrong. It had served us well for years. But suddenly, it was the bottleneck choking the entire engine.
Engineers were spending entire days reviewing instead of building. PRs were waiting 48+ hours to merge. Features that should have shipped in a sprint were waiting in queue. Business velocity was suffering — not because we couldn’t build fast, but because we couldn’t validate fast.
We sat down and made the realization that changed everything:
The rules hadn’t changed. The game had.
You can’t drop a Formula 1 engine into a process designed for 2019 and expect it not to catch fire.
Vibe coding — generating fast and shipping faster — wasn’t an option. We’re a fintech. A bug in our system isn’t a broken UI. It can be a reconciliation gap, an incorrect financial report, or undetected revenue leakage. The cost of being wrong is asymmetric.
So we did the hardest thing: we threw out 15 years of inherited engineering process and rebuilt it from scratch — designed for the AI era, but with discipline as the foundation.
The new playbook.
Here’s the developer experience we built. Four layers.
Layer 0 — Spec-Driven Development (SDD).
Everything starts with a spec. Not a Notion doc nobody reads. A spec written to be executed by an agent.
We use Claude Code with three modes that run in sequence:
- Brainstorm mode — open exploration with the agent. What are the edge cases? What’s the surface area? What might go wrong?
- Planning mode — convert the brainstorm into a structured implementation plan. File-by-file. Test-by-test.
- Execute mode — the agent implements the plan with strict guardrails on scope.
Plus a library of internal skills — reusable prompt templates for our most frequent operations: database migrations, security reviews, debugging production jobs, schema evolution.
The discipline lives in the spec. If the spec is wrong, the code is wrong — which forces clarity before a single line is written.
Layer 1 — Static analysis baseline.
Before any human or agent touches a PR, it goes through 10+ static analyzers, all blocking:
- Linters (Ruff)
- Formatters (Black)
- Security scanners (Bandit, Trivy)
- Type checkers
- Test coverage gates (90% minimum on new code)
- Dependency vulnerability checks (pip-audit)
- Secret scanners
- Architecture rule enforcers (e.g., we ban direct imports of certain libraries — agents and humans both must use our internal abstractions)
Nothing controversial here. This is table stakes. But these analyzers are blocking. Not advisory. The agent and the human both bow to them.
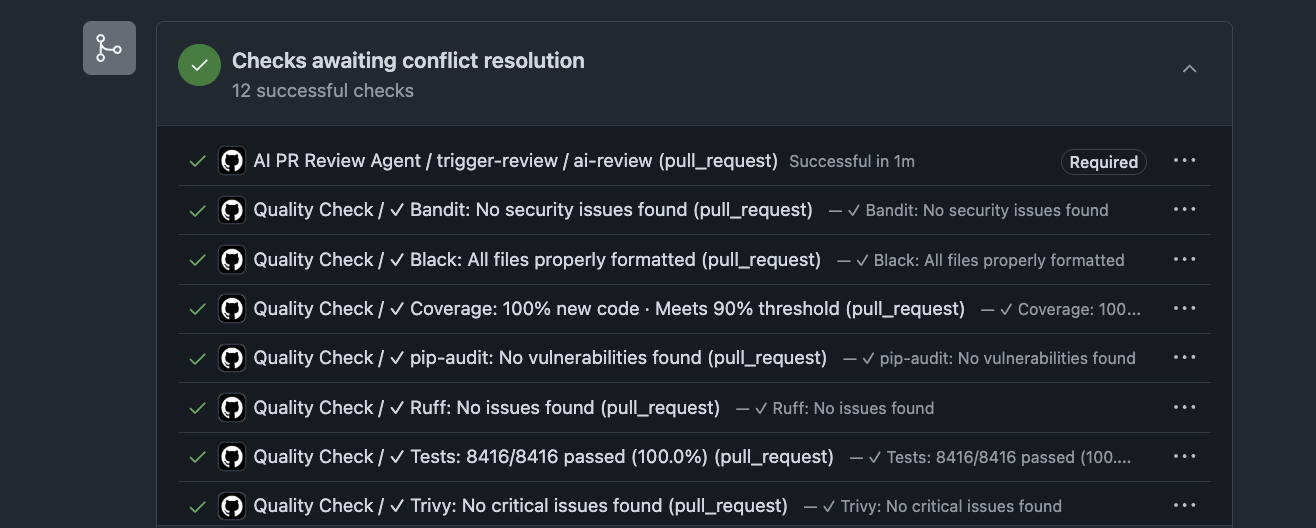
Layer 2 — The PR Review Agent.
This is where we made the bet that flipped our world.
Our PR storm wasn’t going to be solved by hiring more reviewers. We needed something that understood our system as deeply as a senior engineer: our architecture, our codebase, our domain (fintech reconciliation), our security model, and our coding conventions.
So we built one. A custom agent — tuned over weeks, not days — that reviews every PR.
Under the hood, it’s not a single agent. It’s an orchestrated swarm of specialized agents: Security, Code Quality, Architecture, Reconciliation logic, Analytics Engine. Each one runs in parallel, focused on its domain. Their outputs feed an aggregator that synthesizes a single structured review.
The full review costs us less than $0.50 per PR. Less than a coffee. For an unbiased, multi-disciplinary, senior-level review on every change.
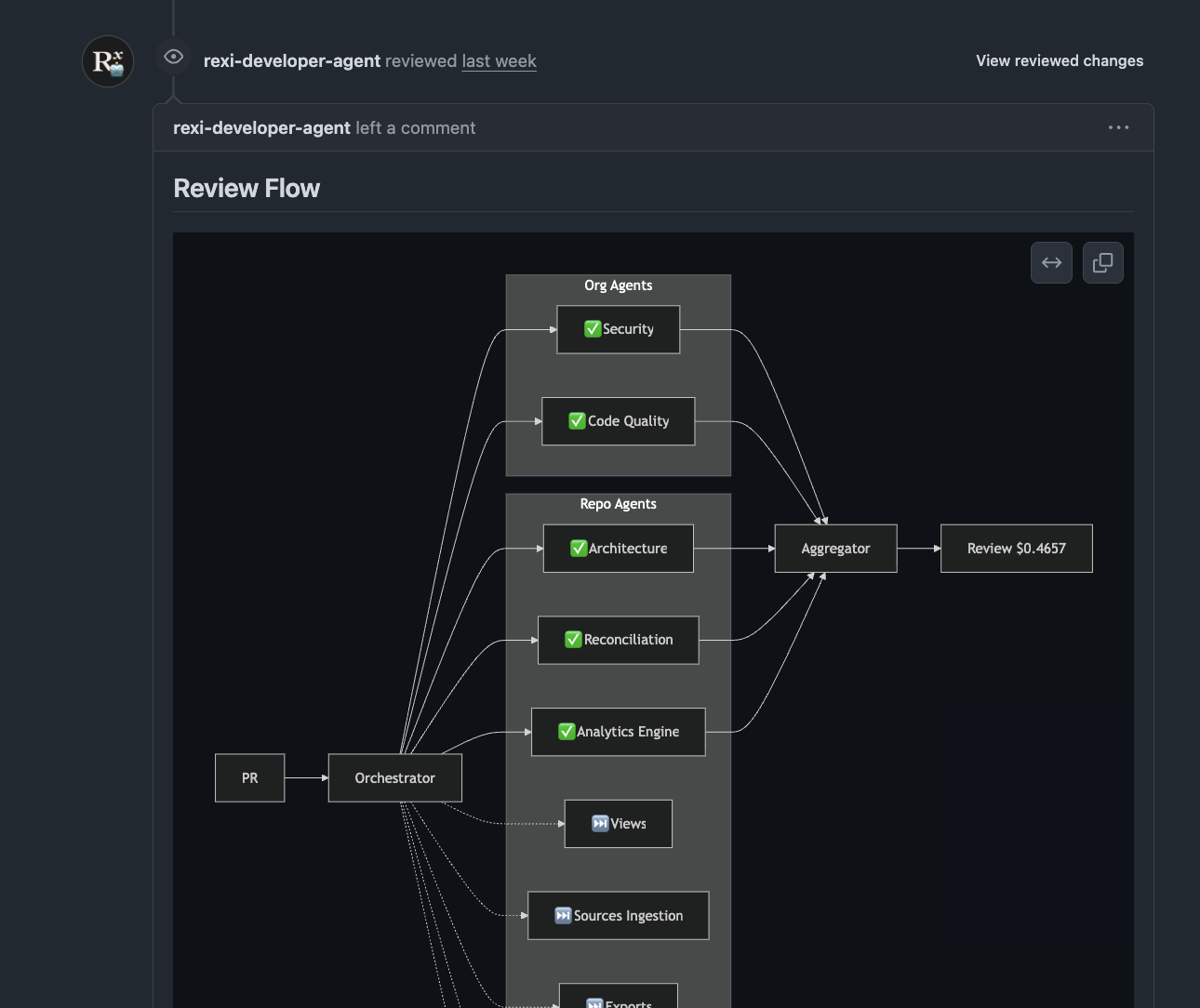
The breakthrough realization came after a few weeks of running it in shadow mode:
A well-tuned review agent isn’t just faster than a human reviewer. It’s better.
Better in specific, measurable ways:
- No bias. It doesn’t approve a PR because it likes the author. It doesn’t reject one because it’s tired.
- Total recall. It remembers every architectural decision we ever made, every internal convention, every past bug we’ve burned.
- Multi-disciplinary. Architecture review, security review, product correctness, test quality, performance considerations — all in one pass.
- Tireless consistency. Review #500 of the day gets the same rigor as review #1.
That led to the most disruptive decision we’ve made:
We removed the requirement of a second human approver.
In the pre-AI era, having another collaborator approve was non-negotiable. It was the sanity check, the second pair of eyes, the bias counterweight.
In our new era, the agent fills that role — better, with humans always remaining in the loop on the decisions (architecture, business risk, scope) but no longer required to be in the mechanics of every line review.
This is how it works in practice:
- The developer opens a PR
- They request review from the agent, the same way they used to request review from a teammate
- A GitHub Action fires automatically and the agent runs
- The agent comments with structured findings: bugs, architectural concerns, security issues, test gaps, best-practice violations, suggested improvements
- The PR cannot merge until all comments are resolved. This is a hard CI gate.
- If the developer pushes new code, the check is invalidated and the agent must run again
The human in the loop is preserved at the level that matters: the developer must read every comment, decide whether to address it or push back with reasoning, and ship a PR they’re proud to put their name on.
What surprised us most: developers learn faster from the agent than they did from each other.
The agent explains its reasoning. It cites our internal architectural docs. It points to similar patterns elsewhere in the codebase. Junior engineers level up at a rate we hadn’t seen with traditional review. The review process became a teaching process.
Layer 3 — QA Agents Platform.
We didn’t stop at code review. We went after the next big bottleneck: QA.
For years, the gold standard for catching real-world regressions was a manual QA team — humans who would actually click around the app, in human ways, finding the edge cases that automated tests miss.
We don’t have a manual QA team. We’re five engineers. So we built something better:
Agents that navigate our platform like real users.
The Rexi QA Monitor runs a fleet of specialized agents — one per product surface (Sources, Reconciliations, Custom QA flows). Each agent:
- Opens the application as a real user would
- Clicks through critical user journeys end-to-end
- Probes edge cases — invalid inputs, race conditions, weird state combinations
- Detects failures, regressions, broken flows
- Reports each finding with priority (P0/P1/P2), description, failing path, and the proposed fix
- Generates an auto-fix PR when the issue is mechanically resolvable, ready for the developer to review and merge
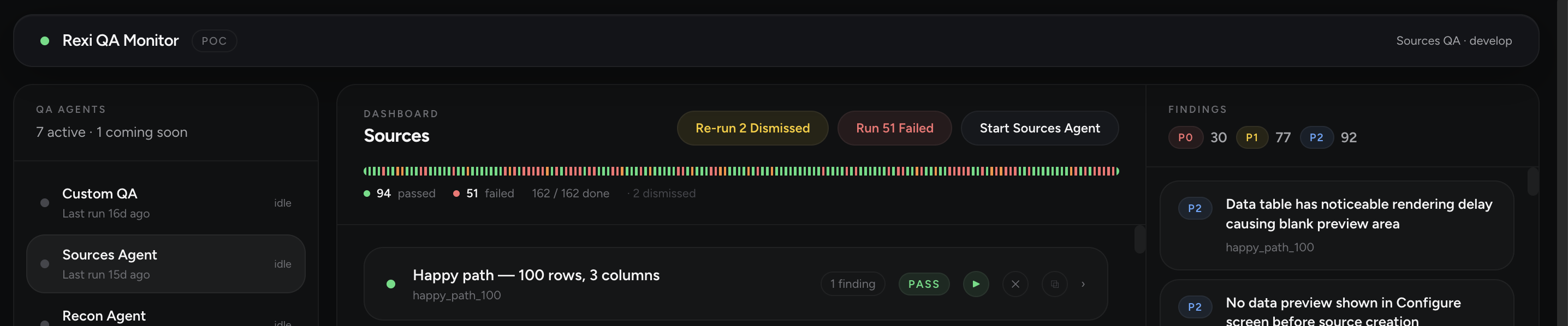
The agents are tireless. They run on every deployment, on a schedule, and on demand. They find regressions that a human QA team — even an excellent one — would miss because they don’t get bored, they don’t get tired, and they don’t have a Friday afternoon.
Combined with the PR Review Agent, this means we have two independent guardrails validating every change before it touches production: one looking at the code itself, one looking at how the code behaves in the real app.
Why this matters more in fintech than anywhere else.
Speed in consumer software is forgiving. A bug in your dashboard means a frustrated user.
Speed in financial infrastructure is not forgiving. A bug here can mean reconciliation gaps, incorrect reporting, regulatory exposure, or undetected revenue leakage. The cost of being wrong is asymmetric — and it lands on someone else’s balance sheet.
The temptation in our industry, watching the AI wave, is binary:
- Option A: stay conservative, ship slowly, miss the curve
- Option B: vibe-code your way to high velocity and pray nothing breaks
Both are wrong. Both will kill a fintech, just on different timelines.
There’s a third option, and it’s the one we’ve been building:
Use AI to ship faster, AND use AI to ship safer.
Not by adding a human as a bottleneck. By building agents whose entire job is rigor. Architecture rigor. Security rigor. Test rigor. Product correctness. The things humans were doing imperfectly because they were tired and biased — done now by systems that don’t get tired and don’t have bias.
The discipline isn’t gone. It’s encoded into the system.
The takeaway.
Altman is right: the world needs so much more code than currently gets written. The companies that internalize what AI actually unlocks — and have the discipline to redesign their processes around it — are going to be impossible to catch.
But “internalize” doesn’t mean “vibe code.” Especially not in fintech.
It means rebuilding your developer experience from first principles. It means firing your old process and hiring a new one. It means having the courage to say “this rule that served us for 15 years no longer fits the game we’re playing.”
In April we shipped 800 deployments with a team of five. The number isn’t the point.
The point is what the number cost: weeks of tuning agents, months of process redesign, and a lot of hard conversations about what to keep and what to throw out.
